Introducing rKenyaCensus


These files can be downloaded from the KNBS website.
The 2019 Kenya Population and Housing Census was the eighth to be conducted in Kenya since 1948 and was conducted from the night of 24th /25th to 31st August 2019. Kenya leveraged on technology to capture data during cartographic mapping, enumeration and data transmission, making the 2019 Census the first paperless census to be conducted in Kenya (KNBS did a good job 👏, 👏, 👏, 👏).
The development version of the package can be installed in R via:
Note: You first have to have devtools installed.
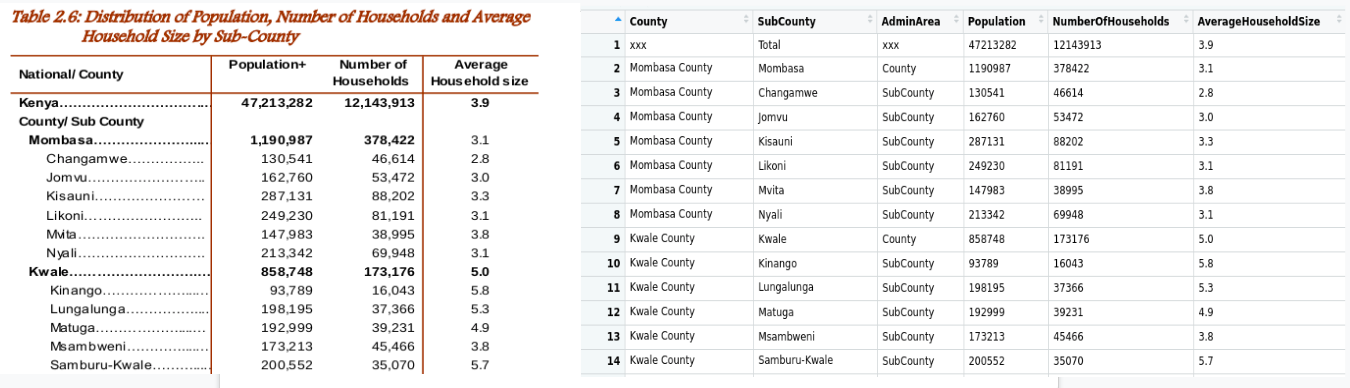
Each table has been scrapped and given a unique identifier, e.g V1.T2.3 is the data in table 2.3 of Volume 1.
The DataCatalogue dataset contains a list of the different datasets that are contained in this package. To learn more about each of the different datasets, run ?datasetname, e.g
?V1_T2.2This opens up a “Help” page where you can get more information about the dataset, as well as the description of each of the variables.

A total of 47,564,296 persons were enumerated during the census, comprising 23,548,056 males, 24,014,716 females and 1,524 intersex.
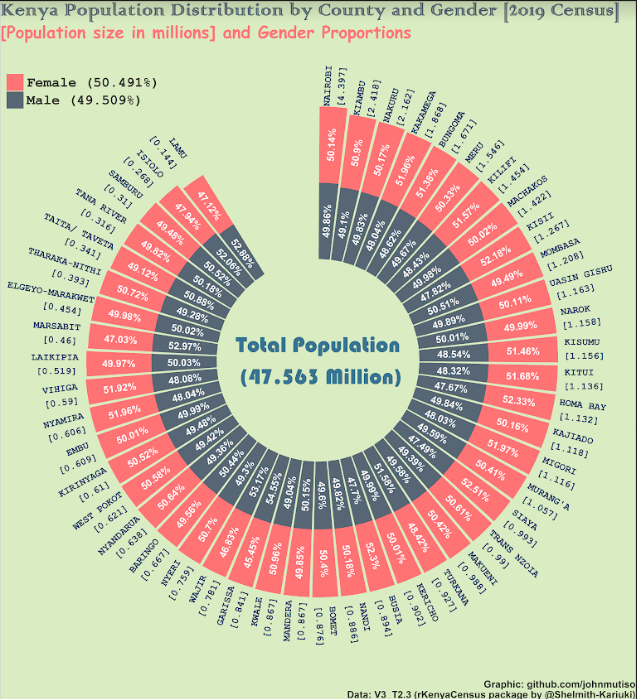
Note: The idea behind the coord polar graph above was to display the population distribution per County and Gender, ordered by decreasing population size. The bars have only been used to distinguish between male and female proportions.
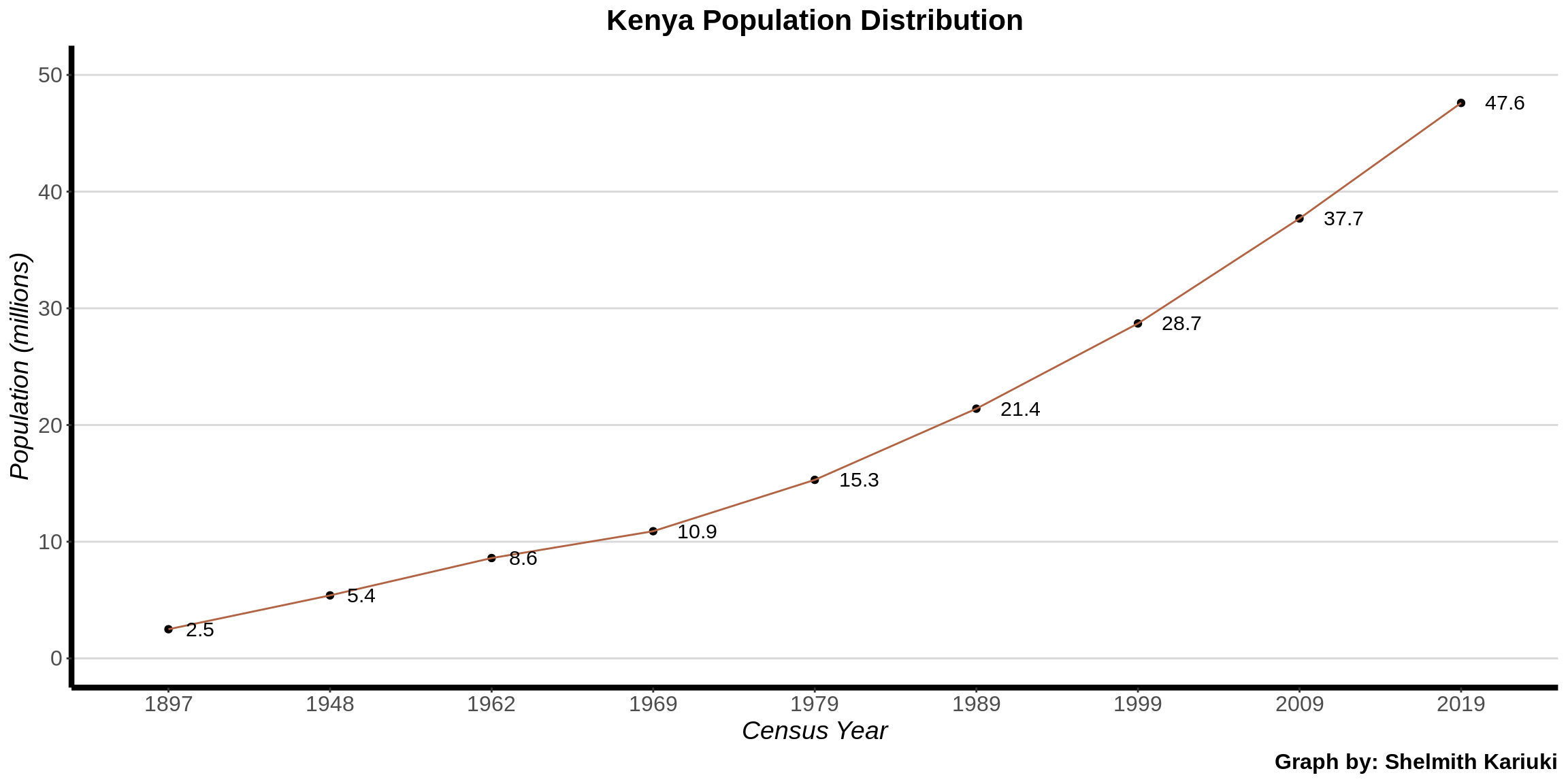
The results indicate a population growth of nine million since the exercise was last carried out 10 years ago.
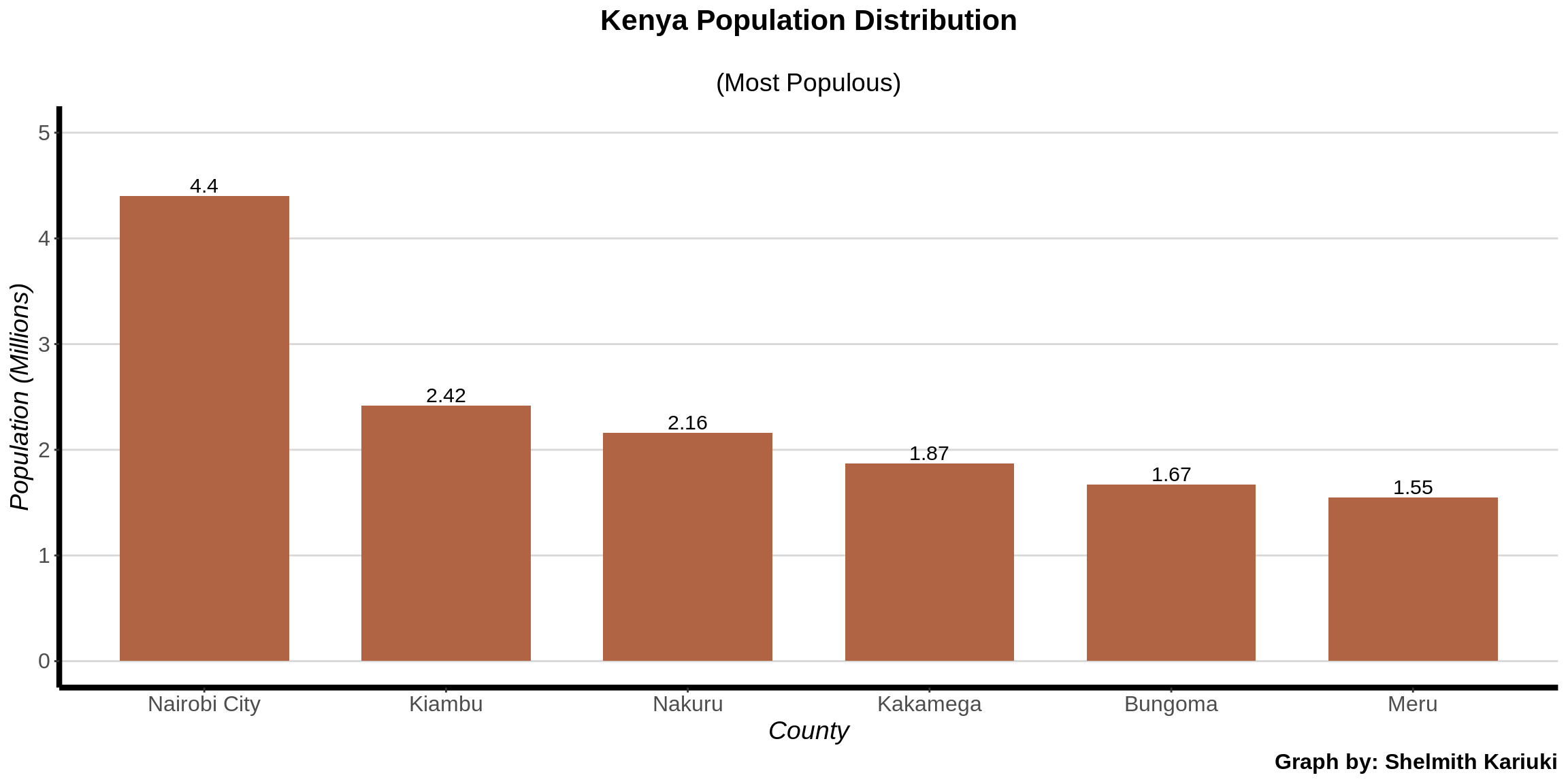
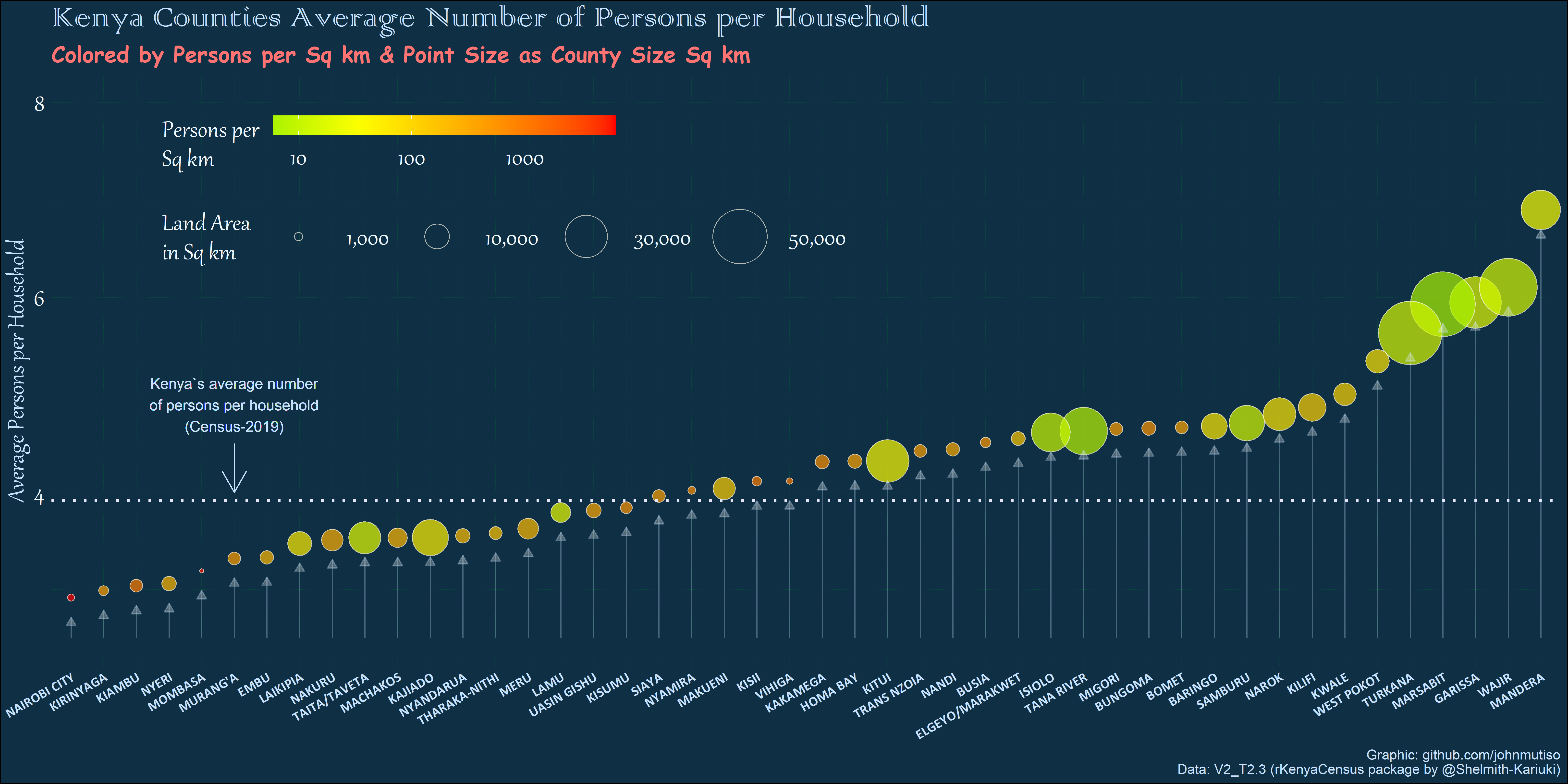
Nairobi, Nakuru and Kiambu registered the highest population counts.
Mandera, Wajir and Garissa registered the highest average household size, while Nairobi, Kirinyaga and Kiambu registered the least average household size.
The process of creating this package was amazing. I used the tabulizer R package to scrap the data from the different pdfs, though I faced a small glitch while trying to scrap two or three of the datasets. For those tables, I used data that had already been scrapped, and was readily available on the internet, even though I had to clean it further. I used the usethis package to “attach” the data onto the package.
I decided to come up with the package for a host of reasons. To begin with, I believe that people prefer working with data when it is in an “easy to use” format, as opposed to it being in pdf format. The data has been simplified so that data analysts can play around with it, without having to go through the “dirty” process themselves. I am hoping that people can use the data to practise data visualizations, and come up with amazing graphs (or better still, amazing shiny dashboards).
I have also always wanted to learn package development through a real life project. I am glad that I can now use the usethis::use_data(xxx, overwrite = T) command, and I know what “r cmd-check” is (thanks to Jenny Bryan for creating and maintaining the package). I also needed to work on a project that I could showcase, during my next interview, incase they ask how I spent my time during the Covid19 pandemic (yes, I am job hunting 😿, 😿, 😿, 😿).
Most of the datasets are exactly as they appear in the pdf files, but for some, I tried manipulating them a little bit so that people could easily use them.
I also got shapefiles of Kenya County boundaries from a friend (thanks Carole), but unfortunately, I was not able to include them in the package. They can be downloaded from this site. I hope that spatial data analysts could use this data to develop awesome maps (I can’t wait to see what you all come up with 💃, 💃, 💃).
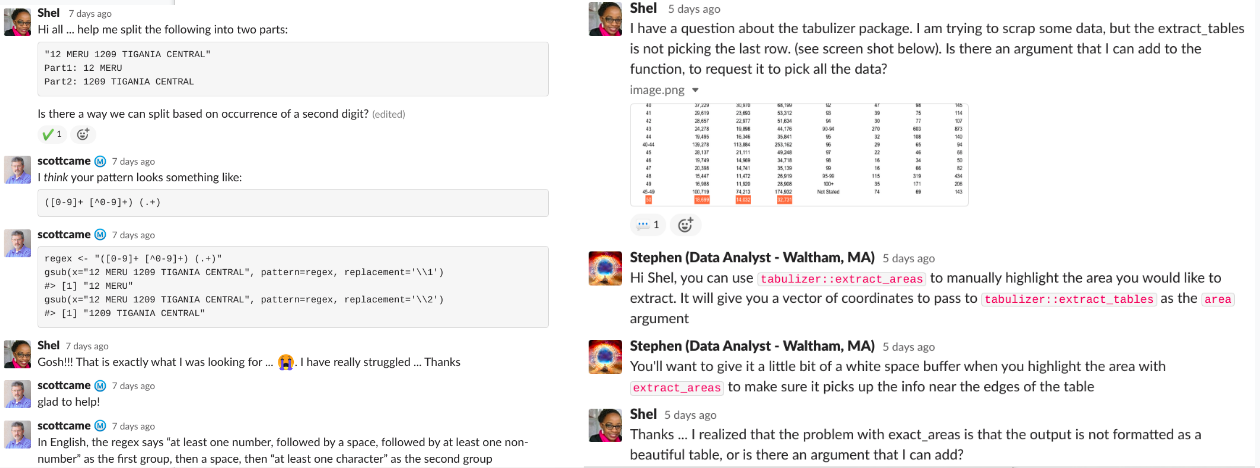
One of the major lessons I learnt from the process is that data cleaning is a very very important skill (well, I have always known this, but I am now more convinced). A huge thanks to my friends at the R4DS community, especially Stephen and Scott Came, who came through when I needed help on certain issues.
I want to appreciate my friends (Tabby, Eric, Nangira, Evelyne, AnnMaureen, Caren and Peter), for taking their time to check the data in the package, against the data in the pdf files. We are confident that this work is error free, but please raise an alarm if you think something is amiss. I also want to thank the amazing John Mutiso, who spent some hours generating some of the amazing graphs that are embedded on this post. Mutiso has been generating awesome #TidyTuesday graphs as well. He was lucky enough to have one of his graphs published in the rweekly.org website (💪, 💪).
Disclaimer alert: This package is still work in progress. The data is being cleaned and refined on a daily basis. Changes (Volume 3) are being pushed to github every afternoon beginning 29th April, 2020. Please keep refreshing (re-installing) the package, so that you have the most updated version. I am yet to work on Volume 4 of the results. I will post an update once I am done with that.
Update: Volume 4 data is ready, and the package has been updated. Volume 4 includes data showing the distribution of school attendance, work activity (those working vs those job hunting), dominant wall, floor and roofing material of main dwelling units, agricultural data (crops and livestock) for each county, data on different types of disabilities, ownership of mobile phones, usage of the internet, percentage of births that take place in a health facility vs those that take place in a non-health facility, etc.
The different datasets can also be downloaded as .csv or .xlsx files, from this shiny app.
I am also hoping to submit the package to CRAN, once the development version is stable.

I am happy to discuss further improvements to the package, so please feel free to contact me through the contact form, at the bottom of this site. Again, incase you come across a bug, please do reach out as well, either via the contact form, or better still, open an issue on github.
Parting shot: If you have an amazing idea, start working on it, the end product will satisfy your soul.
Guess what!! We shall overcome Covid19, but before then, keep safe, stay at home, wash your hands regularly and if you have to leave your premises, please wear a mask. It shall be well.
Stay safe everyone!🇰🇪🇰🇪🇰🇪🇰🇪🇰🇪🇰🇪🇰🇪🇰🇪🇰🇪🇰🇪🇰🇪🇰🇪🇰🇪🇰🇪🇰🇪🇰🇪🇰🇪🇰🇪🇰🇪
